


Almatani, Mohammed Khalid*
*Industrial Engineering Dept., College of Engineering, King Saud University, Saudi Arabia
Abstract #
Human errors are significant contributors to the overall risk in the industry. In fact, 80% of marine failures and shipping accidents are caused by human errors. Human errors, additionally, are often a root or significant cause of a system failure which could lead to tremendous undesirable consequences such as fatalities and financial losses. Currently, most industries use the latest technologies in order to maximise the availability and reliability of their equipment and minimise human interventions. However, the human role is still vital in different phases of a plant life cycle, especially during maintenance. Traditional Reliability, Availability and Maintainability (RAM) methodology, a well-known methodology for optimising maintenance strategies in an organisation, does not incorporate human reliability analysis. Therefore, this research aims to develop a novel framework for improved maintenance engineering decision-making, which can be achieved by fusing probabilistic human and hardware availability assessment techniques. The proposed framework has a systematic process that helps analysts, engineers, and decision-makers consider and manage risk effectively in a complex system. A publicly available case study in an offshore oil and gas platform is selected as an example for demonstration purposes. The values of human error probabilities (HEPs) for maintenance activities are calculated by using the Human Error Assessment and Reduction Technique (HEART). These maintenance activities’ reliability values are improved by using a novel Human-based Decision-Making Grid (H-DMG). This framework, including H-DMG, can improve a system’s availability, reduce downtime cost, and reduce human errors.
Keywords: Reliability Availability and Maintainability; Human Reliability Assessment; Decision-Making Grid.
1 Introduction #
There has been a significant change over the past eight decades in maintenance engineering practices. This change has affected maintenance engineering’s concepts, techniques, and technology. In addition, organisations have become more aware of the significant impact of maintenance engineering on businesses. Historically, Maintenance engineering is divided into three generations [1]. Simple corrective maintenance, i.e. ‘operate and fix’ when fails, was considered as the first generation. Preventive maintenance, which was considered as the second generation, is developed during the Second World War. Preventive maintenance aims to increase equipment reliability, extend an asset utilisation, and reduce maintenance cost. Later, when equipment has become more complex, maintenance techniques and technology such as Failure Mode Effect and Criticality Analysis (FMECA), Reliability-centred Maintenance (RCM), condition-based maintenance (CBM) were developed. This was the beginning of the third generation. Recently, a fourth industrial revolution has begun. Industry 4.0, which was first mentioned in Germany 2011 [2], can be defined ‘the integration of complex physical machinery and devices with networked sensors and software, used to predict, control and plan for better business and societal outcomes’ [3]. Another defines Industry 4.0 is ‘the technological integration of cyber-physical systems (CPS) in the production process’ [4]. This revolution has many associated terms which could include cyber- physical systems (CPS), Internet of Things (IoT), Industrial Internet of Things (IIoT), big data, smart manufacturing, etc. Industry 4.0 could change traditional maintenance practices by digitising and automating production systems and introducing a new connectivity method in the whole supply chain [2].
Although these technologies have advanced modern maintenance practices in the industry, human errors in maintenance activities are still inadequately assessed. In fact, human and organisational factors (HOF) have a significant impact on asset value. Still, some organisations neglect considering or reviewing human errors that could cause a system’s failure [5]. As a result, this research aims to address this problem.
1.1 Research purpose #
Human errors are considered a major contributor to the risk in the industry. In fact, over 37% of the US railways accidents are caused by human errors [6]. Also, 80% of offshore oil and gas failures are caused by human errors [7, 8]. Further, 80% of these failures can occur during maintenance activities [9]. This has led to catastrophic consequences that urge the need to study, understand, analyse, and evaluate human errors to help designers and engineers eliminate or reduce risk. Traditionally, a reliability, availability, and maintainability (RAM) analysis does not consider human reliability assessment (HRA). This could be due to the lack of data in a particular industry [10]. Although some methodologies could consider human factors within a design process [11] collecting and assessing the necessary data can be challenging [12]. Further, although there are several optimisation techniques for maintenance strategies such Decision-Making Grid (DMG) [13 – 17], these DMGs do not provide actions or measures to reduce human errors in maintenance activities. Therefore, new techniques and models are required to tackle this gap, and this research aims to address this problem.
This research aims to develop a novel framework for improved maintenance engineering decision-making, which can be achieved by fusing probabilistic human and hardware availability assessment techniques. This framework can help analysts and decision-makers to identify, manage and reduce potential risk in a complex system effectively.
This paper is structured as follows. Section 1 introduces the problem statement and objective of this study. Section 2 reviews briefly common HRA methods, human error classification, and some of the decision – making grid. Section 3 illustrates the development of the framework. Section 4 illustrates the application of the developed framework. Section 5 concludes this study.
2 Literature Review #
2.1 Availability #
There is a significant demand in many industries to produce and operate to the level of free defects or free failures. In addition, today’s demand expects to functionally operate safely and without causing any hazards that could lead to catastrophic consequences. In order to achieve the previous targets, there is a need to study and assess equipment reliability as well as human reliability. Reliability engineering is a vast discipline of system engineering, and it is becoming more involved with the emergence of Industry 4.0. The main objective of reliability engineering is to identify, assess, and prevent the likelihood of failures by applying engineering knowledge and techniques. Reliability of a piece of equipment can be defined as the successful probability of this equipment to perform a task, under operational conditions, without failures, during a specific time [18]. It is important to mention that failures can be identified when there is a total loss of production or a complete shutdown. However, a partial loss in production or a delayed train, for example, can be considered a failure in some high-reliability organization [19]. Generally, the availability of a piece of equipment can be affected by several factors: the reliability of that piece of equipment, maintainability, supportability, maintenance strategies, and accessibility, as shown in Figure 1 [20]. So, in order to estimate the actual availability of a system, there is a need to calculate the theoretical availability, first, which is affected by the reliability, maintainability and supportability of that system. Once the theoretical availability of a system has been calculated, both maintenance strategies and accessibility factors, which include human factors, can be considered to estimate the actual availability of a system.
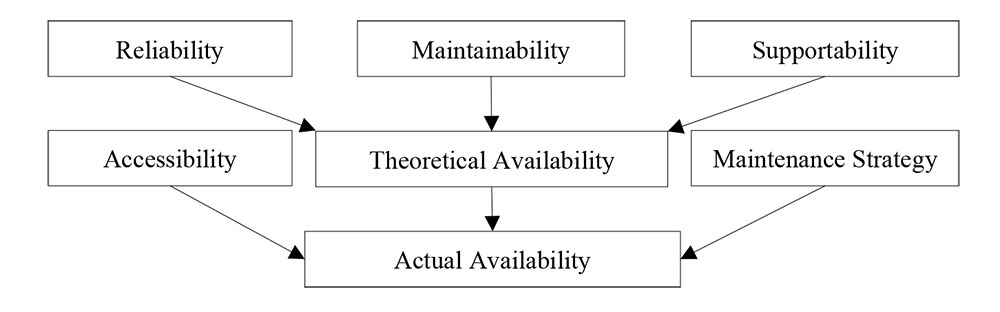
Figure 1 Factors affecting actual availability [13]
2.2 Human Reliability Assessment #
There are many areas where human reliability assessment (HRA) can be used. First, in the design phase of a system when humans are involved, their behaviours can affect the overall system. Second, during the licencing discussion, a system can meet safety or legislation requirements. Third, HRA can be used during the modification of a system [21]. Finally, HRA can be considered as a robust assessment in any plant life cycle stage [22]. Although most industries are moving toward fully automated production or process, still there is a need for a human element to interact with equipment specifically during a maintenance task. Traditionally, the influence of a human being on system reliability is omitted from a quantitative perspective. This has motivated many researchers to study and develop several methods that assess human reliability in a Man-Machine System (MMS). Figure 2 illustrates the interaction between a human being and a technical component (e.g., a pump or a compressor) and how can some factors influence the reliability of both.
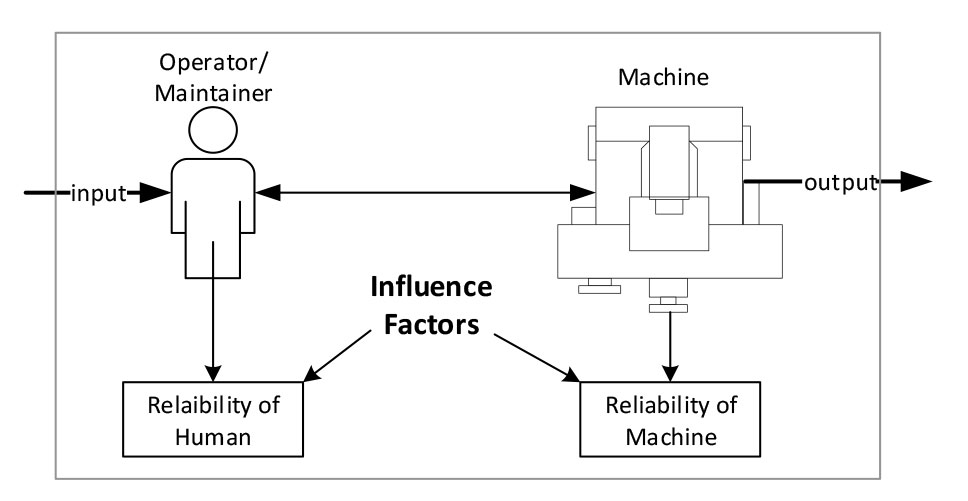 Figure 2 Human and technical reliability in MMS [23]
Figure 2 Human and technical reliability in MMS [23]
Human reliability assessment (HRA) can be considered as a subsection in the field of reliability engineering although the founders of the most utilised human reliability assessment methods are psychologists. A human reliability assessment can be defined as ‘a systematic identification and evaluation of the possible errors that may be made by technicians, maintenance personnel, and other personnel in the system’ [24]. An HRA activity’s objective is to maximise the workforce’s performance, which will improve the overall effectiveness of an organisation and minimise the impact of potential risks. Therefore, reliable human performance is when individuals perform a task, make a decision, or respond to action according to their organisations’ expectations [25]. In literature, researchers classify HRA methods into two generations. The HRA first generation is developed based on the study of human error probability and does not consider the cause of behaviour [26]. Some of these methods are: Technique for Human Error Rate Prediction (THERP) [27], Accident Sequence Evaluation Program (ASEP) [28], Human Error Assessment and Reduction Technique (HEART) [29], and Simplified Plant Analysis Risk Human Reliability Assessment (SPAR-H) [30]. These methods break a task into component parts to calculate human error probabilities (HEPs) and later consider potential impact of modifying factors such as pressure and stress [23]. The second-generation methods consider the context as a factor affecting human performance failure and later evaluate the relationship between the context and HEPs [8]. Some of these methods are: A Technique for Human Event Analysis (ATHEANA) [31], and Cognitive Reliability and Error Analysis Method (CREAM) [32]. These methods consider cognitive behaviour of the human. The activities of the human are assumed as performed for specific purpose. Some researchers have added a third generation in HRA methods, which considers dynamic simulation system with a virtual representation of human to determine challenging human performance situations [26].
2.2.1 HRA process
There are seven main steps to perform a complete human reliability assessment study, illustrated in Figure 3. The first step is formulating a scenario which could be performing a maintenance task in a separator. The second step is to collect the required data for the formulated scenario. The third step is to analyse the task. The Hierarchal Task Analysis (HTA), which is a top-down approach, breaks a task into sub-tasks and multiple levels in order to achieve the desired goal (i.e. top-level task) [33].

Figure 3 A generic human reliability analysis process
It should be noted that critical tasks should be identified during this step. A critical task is a task that if it is not performed adequately, and according to a standard procedure, it could lead to highly undesirable consequences [25]. The fourth step is to identify the human errors. The fifth step is to model the identified human errors by using, for example, FTA, Event Tree, etc. This sixth step is to quantify human errors. Some of the published methods only quantify human errors and fail to provide a reduction technique [34]. The last step, and most importantly, is to perform a human error reduction activity. The human error probability (HEP), which is estimated by Equation – 1, can be defined as the number of errors (z) which are caused by human over the total number of potential errors (n) during tasks [35].
![]()
(Equation – 1)
2.2.2 Human error classification & causes
The previous sections have mentioned the term Human Errors several times. Therefore, there is a need to define it and understand its classifications. Thus, human error can be defined as “an action that goes beyond the acceptable limits, those being defined by the system” [27]. There are three main classifications for human error in literature including a) the Skill – Rule – Knowledge classification [36], b) commission and omission errors [27], c) error and violation classification [37]. Also, there is a need to understand what the possible causes behind them are. Initially, unlike equipment, a human being’s behaviour is hard to predict. Similarly, human errors could occur during any phase of the system lifecycle. There are three main aspects where human errors are linked to [32]. First, individual aspects are linked to the ability, psychological and physical characteristics of a person. Some of these aspects cannot be changed; however, some could be improved by learning and training. Second, technological aspects are linked to the interaction between a human and a machine. Last, organisational aspects are linked to an organisation’s culture, and these aspects have a significant impact on both previous aspects [21]. It should be noted that the performance of individuals, organisations, hardware, and software can be affected by environmental factors as well. These environmental factors are classified into external, internal, and sociological factors. External factors could include wind, temperature, rain, and time of day. Internal factors can include lighting, ventilation, and noise. Sociological factors could include values, beliefs and moral.
2.2.3 Human error in maintenance
The impact of human errors in maintenance are reviewed [38]. This review aims to increase the awareness of maintenance practitioners on the impact of human errors in maintenance and develop mitigation actions. Generally, the study suggests six classifications of human error which could include operating errors, assembly errors, design errors, inspection errors, installation errors, and maintenance errors. Often, maintenance error could occur due to inadequate repair or preventive actions. This paper can be a useful reference for researchers who are concerned about human error in maintenance. Similarly, 78 publications on human factors in maintenance are reviewed in order to identify critical human error influencing factors [16]. The study finds that equipment reliability and human error are a primary concern in the industry. This study reports that fatigue, lack of experience, and inadequate communication are the most critical human influencing factors related to maintenance. The study concludes that some future directions could include predicting human error in maintenance and how they can affect the reliability of a system. Another study suggests that human errors can affect the availability and performance of equipment and products’ quality [39]. A piece of research is conducted to identify critical human error influencing factors in maintenance activities within a petroleum facility [40]. They conduct a structured interview with 38 maintenance technicians. The study finds that the most critical human error influencing factors, which could lead to maintenance failures, are flawed assumptions, poor design and maintenance practices and poor communication. Although maintenance technicians answer the survey, it would be beneficial if they could have access to supervisors or top management. In addition, this study is limited to a single facility, and it would be beneficial if more organisations are included.
2.3 Decision-Making Grid #
The first decision-making grid (DMG), which can be seen in Figure 4, was developed by Labib in 1996 [13]. Later, this DMG has become a good decision-making technique to improve maintenance practice and reduce downtime. A DMG’s objective is to provide a systematic and consistent methodology to select an appropriate maintenance strategy for a given piece of equipment to reduce both downtime and failure frequency [41]. These maintenance strategies are operate-to- failure (OTF), condition-based maintenance (CBM), total productive maintenance (TPM), skill level upgrade (SLU), and design out maintenance or machine (DOM). Simply, the objective of the DMG is moving problematic machines into the top-left corner. a detailed explanation of how to use these maintenance strategies are explained in [42]. Although the DMG considers upgrading ‘operators’ skills to perform some maintenance tasks, it does not consider some improvement measures to reduce human errors in maintenance. Therefore, this research aims to address this problem.
| Downtime | ||||
| Low0 – 10 Hrs | Medium 11 – 20 Hrs | High> 20 Hrs | ||
| Frequency | Low0 – 5 failures | OTF | TPM TPM | CBM |
| Medium6 – 10 failures | TPM | TPM | ||
| High> 10 failures | SLU | TPM DOM(A) | ||
Figure 4 Original DMG
3 Method Development #
This research develops a framework by fusing probabilistic techniques for human and hardware availability assessment, as shown in Figure 5. This framework’s novelty can be seen in the integration process of probabilistic techniques and providing a human-based decision-making grid (H-DMG), which can help reduce human error probability (HEP) in a given maintenance task.

3.1 Developing a Human-based Decision-Making Grid (H-DMG) #
The overall objective of this H-DMG is to reduce the probability of human error (HEP) and minimise the associated active repair time (Ha-MTTR). This can be achieved by implementing the human error control measures (HECMs) identified in the literature review. The H-DMG can be divided into three zones: Critical, Critical – Moderate, and Moderate – Low. First, the critical zone requires at least three HECMs, as shown in Figure 6. These HECMs are: i) improve supervision, ii) reduce task complexity, and iii) improve or design out procedure. These measures are incredibly vital to reduce the probability of human error for a given task and minimise the duration of an asset’s active repair time. Second, the critical to moderate zone requires at least two HECMs. For example, suppose the human error probability for a given maintenance task is high, and the associated active repair time is moderate. In that case, the required HECMs are i) improve man- machine interface and ii) control time pressure. Finally, the moderate to low zone requires at least one HECM. For instance, if the HEP for a given task is moderate and the Ha-MTTR is low, the required HECM can be improve training and enhance competence.
This H-DMG is tested in a simulated case study in the following section. Since this research will use the HEART method, described in [29].
| Ha-MTTR | ||||
| Low0 – 8 hours | Moderate 9 – 24 hours | High>24 Hours | ||
| HEP | Low0.001 – 0.01 | Improve team communication and documentation | Improve supervision | Reduce task complexity &Improve supervision |
| Moderate0.01 – 0.1 | Improve training and enhance competence | Improve team communication and documentation&Improve training and enhance competence | Improve supervision &Reduce task complexity | |
| High0.1 – 1 | Improve training and enhance competence &Improve /Design out procedure | Improve Man-Machine interface&Control time pressure | Improve supervision,Reduce task complexity &Improve /Design out procedure | |
Figure 6 The developed H-DMG
3.2 Developing a Framework for Improved Maintenance Engineering Decision-Making #
This section introduces and explains the developed framework for improved maintenance engineering decision-making. The framework, which is illustrated in Figure 7consists of four main phases: a) asset selection and data gathering, b) system modelling and simulation, c) criticality analysis, and d) sensitivity analysis and risk reduction.
Phase one: Asset selection and data gathering
The first phase consists of scope definition, asset(s) selection, data gathering, and conducting a feasibility study. First, scope definition can include the analysis objectives, the available time, teams’ roles and responsibilities, and the business requirements. Second, asset selection can include identifying the boundaries of selected assets and stating any critical analysis assumptions. Third, data gathering includes historical failure rates, failure modes, repair times, spare parts, maintenance crew and logistics. These data can be retrieved from a computerised maintenance management system (CMMS) if possible. Alternatively, if these data are not available in the CMMS of an organization, they can be extracted from original equipment manufacturer (OEM) catalogues. Last, there is a need to check the feasibility of an intended study. Analysts should ensure that all the previous steps are completed before proceeding to the next phase. This is a critical step in this framework because if, for example, the scope is insufficiently defined, the output of the analysis will probably be inadequate, and inaccurate decisions might be taken. If the study is feasible, it is possible now to proceed to the next phase.
Phase two: System modelling and simulation
The second phase consists of system modelling and simulation. Initially, System modelling can be constructed by using reliability block diagram (RBD). The required data for this subprocess is the mean time to failure (MTTF) and main time to repair (MTTR) for the selected assets. Simultaneously, an HRA can be conducted for the maintenance procedures of the selected assets. The HRA’s objective in this phase is to generate a HEP value for each activity of a maintenance procedure and then incorporate this value into the simulation process. The system simulation, where the mean availability of a system can be estimated, can consider both the reliability of an asset and the reliability of a maintenance procedure for that asset. This step can be carried out by a well-recognised approach such as Monte Carlo simulation.
 Figure 7 The Developed Framework for Improved Maintenance Engineering Decision-Making
Figure 7 The Developed Framework for Improved Maintenance Engineering Decision-Making
Phase three: Criticality analysis
Once a system has been simulated, and the mean availability is estimated, criticality analysis should be conducted. During this phase, analysts can identify critical asset(s), component(s) or failure mode(s) that significantly impact the unavailability of the system. Similarly, maintenance procedure(s) or subtask(s) that could cause a total loss of production or undesirable events can be identified.
Phase four: Sensitivity analysis and risk reduction
The last phase is sensitivity analysis and risk reduction, where improvements and actions are needed to reduce failures and increase system availability. First, analysts can check if the conducted study’s output meets the stated objectives and the RAMS target. If the output of the study does not meet the RAMS target, maintenance policies can be revised, and certain decisions for improvement regarding equipment redundancy, for example, can be taken. At the same time, if the HEP value(s) for a given maintenance procedure is not as low as reasonably practicable (ALARP), analysts can apply the novel H-DMG in order to reduce the probability of errors. A good practice when conducting this framework is creating different scenarios and assumptions to determine which one has a cost-effective and safe impact on the availability of a system. Lastly, conducting this framework can be complex and has a significant amount of information. Therefore, analysts can document the output of this framework, and it is important to state the recommended improvements and actions adequately.
4 Application of the framework: A case study #
This research considers a typical offshore oil and gas production facility as a case study. Generally, there are five stages in which oil and gas can be processed [43]. The first stage is the exploration of oil and gas, including prospecting, seismic and drilling activities. These activities are carried out before the development of an oil and gas field. The second stage, which is known as the upstream, is the production of oil and gas. Production facilities in this stage can be located onshore or offshore. The third stage, known as midstream, consists of transporting oil and gas via pipelines, chips, or tanker vehicles. Midstream can include the storage of crude oil and gas. The fourth stage, which is known as downstream, is refining oil and condensate into marketable products. The last stage is processing and producing petrochemical products such as plastic and fertilizer.
4.1 Case study scope, boundaries, assumptions, and limitations #
This section defines the scope, boundaries and assets selection for an offshore oil and gas production facility. This is the first phase when applying the novel framework for improved maintenance engineering decision-making.
Scope and boundaries
A typical offshore oil and gas production system consists of power and heat generation system, process plant, produced water and seawater treatment system, and subsea systems. This case study considers the process plant systems only. The process plant can include production manifolds, a separation train, export pump(s), recompression train, gas treatment train(s), and fuel gas system. This production facility can be considered a medium-size offshore platform, seen in Figure 8. It has one separation train, one gas recompression train, and one gas treatment train. The produced oil rate can be 40,000 BPD after the separation process. Part of the processed gas is used to power the platform, and the rest is injected to the well. At this stage, the processed gas is not exported.
Case study boundaries
- This case study considers the process plant of an offshore topside platform.
- This case study considers corrective maintenance tasks.
- This case study excludes inspection tasks, preventive maintenance tasks and major shutdowns.
- This case study does not consider the power and heat generation systems, process sensors, fire and gas detectors, pipelines, valves, and logic controls.
- Each equipment unit has a predefined system boundary which can be seen in Appendix C.1.
- The reliability data are extracted from the publicly available Offshore Reliability Data OREDA [44].
Assumptions and limitations
It is imperative to identify relevant assumptions and limitations of a production system when conducting a RAMS Analysis. The RAMS analysis’s quality can be significantly affected by these assumptions. For example, optimistic assessments and results can be driven by unrealistic or inadequate assumptions. Also, the accuracy of a RAMS assessment depends on the quality of the reliability data in order to reflect a realistic operational scenario. Therefore, the RAMS assumptions should be measurable, unambiguous, and easy to understand. A list of assumptions and limitations considered when conducting this analysis are listed below.
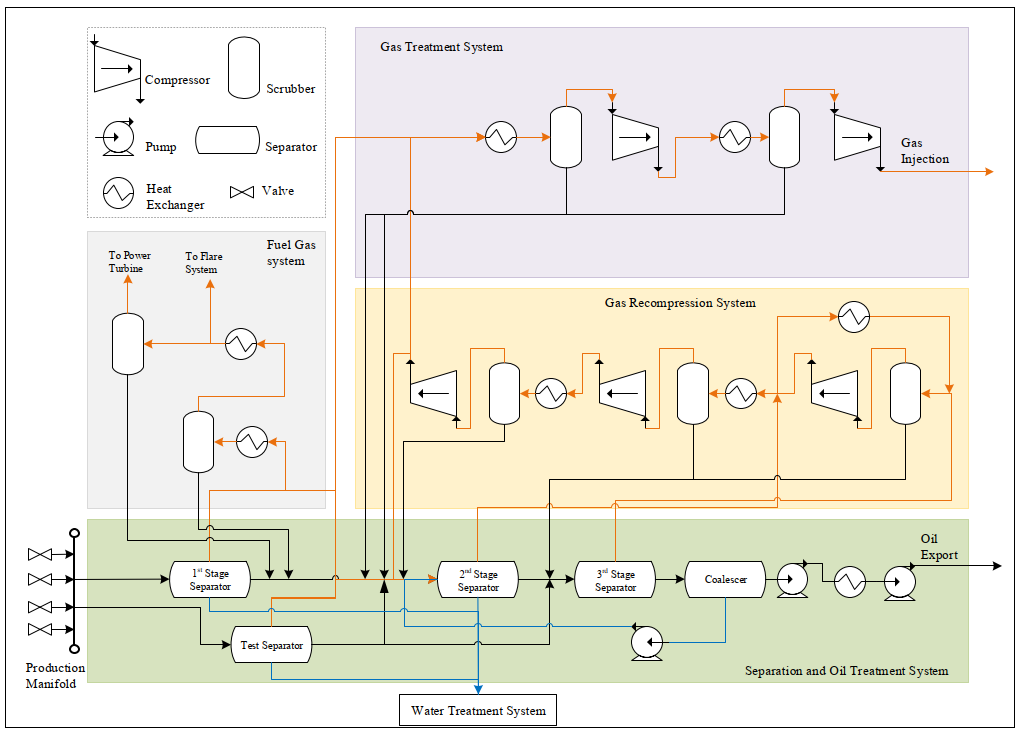 Figure Error! No text of specified style in document. A typical offshore oil and gas process plant [45]
Figure Error! No text of specified style in document. A typical offshore oil and gas process plant [45]
- This case study assumes that considered failure modes are critical. This means that if a failure mode occurs, an equipment unit will shut down and cause a total loss of production.
- This case study assumes that failure rates are constant, i.e. the failure rates are exponentially distributed. This means that the simulation is conducting during the useful life phase of an equipment unit.
- This case study assumes that all failures are independent. This means that if a failure occurs in one system, it does not trigger another failure.
- This case study assumes that all equipment units are not deteriorating, which means that a repaired component is as good as new after repair.
- The simulation time of this case study is limited to 10 years. This is mainly because new investment decisions for offshore oil and gas platforms can be taken every 5-10 years [22].
- The number of simulations is limited to 1,000 runs. This is mainly because the desired results can be presented as the average results over these multiple runs.
- This case study assumes that a maintenance crew is available on-site in order to avoid backlog and delays.
- This study assumes that there are some logistic delays for each failure mode.
- This case study assumes that the downtime cost is £20,000 per hour.
System overview and objectives
This simulation aims to determine the mean availability of the process plant, uptime, total downtime, MTBF, MTTR, expected number of failures, failure downtime, number of corrective maintenance tasks, corrective maintenance downtime, and system downtime cost. This simulation’s mean availability target is 95%.
4.2 Modelling, simulating, and improving the selected case study #
The second phase is system modelling and simulation. There are four scenarios which will be modelled and simulated. The first scenario is modelling and simulating the selected process plant based on equipment critical modes only. It should be noted that human reliability assessment is not considered in the first scenario. The second scenario is modelling and simulating the selected process plant based on critical failure modes and HEPs. The objective of modelling and simulating these two scenarios is to demonstrate the effect of human errors on a system availability. The third scenario is improving the selected process plant by reducing the HEPs in order to demonstrate how a system can be improved by using the developed H-DMG. The last scenario is improving the selected process plant by reducing the HEPs and implementing a system redundancy in order to demonstrate how a system availability can be improved. In general, when modelling an offshore oil and gas process plant, the RBD is presented in a series configuration [22]. This means that if a piece of equipment fails, the overall production system will be stopped.
Scenario One: Modelling and simulating the process plant based on equipment critical failure modes level
As introduced above, the first scenario is modelling and simulating the selected process plant based on equipment critical modes only. and the simulation results can be seen in Table 1. It can be noticed that the mean availability of the process plant is 95.50% over a period of 10 years. In addition, the total downtime during these ten years is 3,547 hours, and the number of failures is 108 failures. Based on the simulation, the estimated total downtime cost is almost £71 million. It should be mentioned that this is not an adequate assessment of a system availability because it did not consider HEPs.
Table 1 Simulation results for the first scenario
| System Overview | |
| Mean Availability | 95.50% |
| Expected Number of Failures: | 108 |
| Corrective Maintenance Downtime (Hr): | 3,547 |
| System Downtime Cost: | £71m |
Scenario Two: Modelling and simulating the system based on equipment critical failure modes and human error probabilities
As mentioned above, the second scenario is modelling and simulating the selected process plant based on critical failure modes and HEPs. The objective of this scenario is to demonstrate the effect of human errors on a system’s availability. Also, the HEART method is used to estimate the values of HEPs for a hypothetical maintenance task for repairing the export pump. This maintenance task includes 35 activities, which is based on [46] and [7]. This maintenance task includes pump’s isolation, connecting and reinstating activities. It should be noted that the generic HEP is 0.001, and the Assess Proportion of Affect (APOA) for all activities is assumed to be 1. The reliability values of these activities are shown in Figure 9-11.
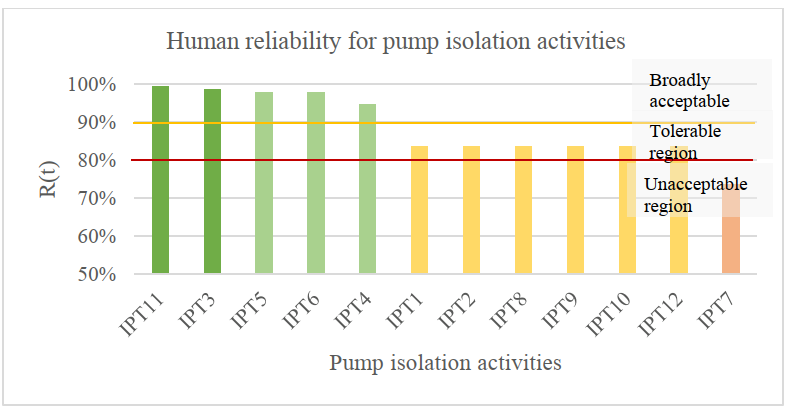
Figure 9 The estimated reliability for the pump isolation activities
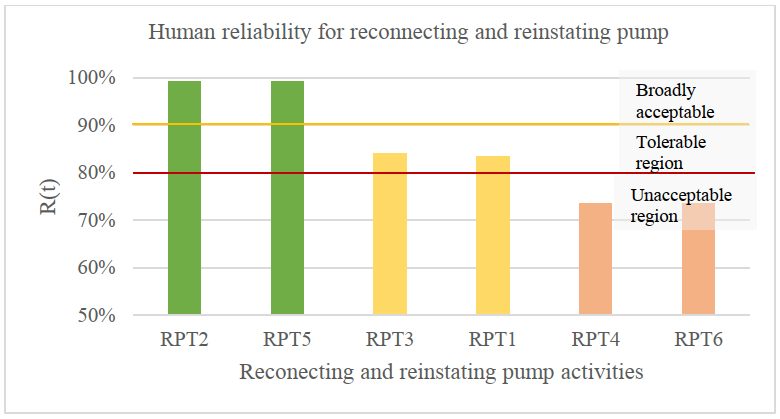
Figure 10 The estimated reliability for the pump reconnecting activities
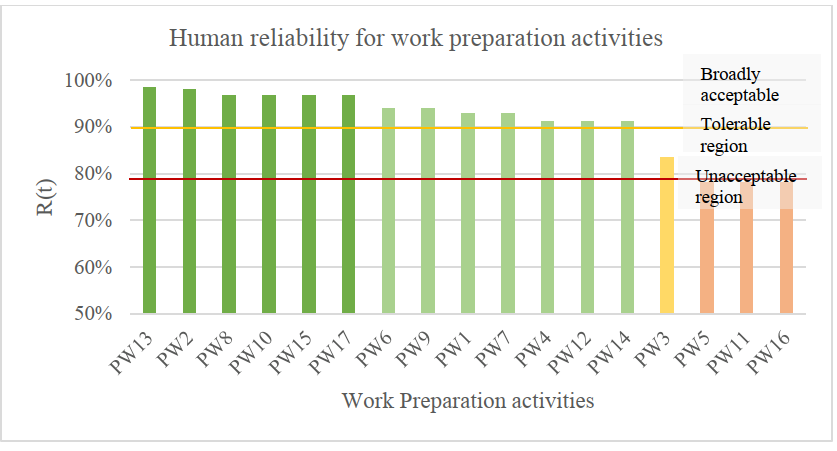
Figure11 The estimated reliability for work preparation activities
The simulation results can be seen in Table 2, and it can be noticed that the mean availability of the process plant is reduced to 91.30% over a period of 10 years. Additionally, the total downtime during these ten years is almost doubled to 6,852 hours, and the number of failures is 110 failures. Although the number of failures has increased by two failures only, these two failures could have a significant and adverse impact on the platform. In fact, it can be noticed that the estimated total downtime cost has been increased to almost £137 million. This scenario can be considered as a real representation of a system’s availability. Further, the simulation results do not meet the targets of this study.
Table 2: Simulation results for the second scenario
| System Overview | |
| Mean Availability (All Events): | 91.30% |
| Expected Number of Failures: | 110 |
| CM Downtime (Hr): | 6,852 |
| System Downtime Cost: | £137m |
Improvement One: an improved offshore oil and gas topside systems by reducing HEPs
Since the previous scenario did not meet the target of this study, there is a need to improve the system by, identifying critical assets and maintenance procedures, and then providing some recommendations using the H-DMG. The most critical maintenance activities that have a significant impact on the process plant unavailability are:
- Perform pressure test & isolation valves
- Test pressure
- Opening valves, filling pump, and testing for leaks
- Perform a risk assessment of activity
- Perform and document initial gas test
- Workforce supervisor (WFS) hold toolbox meeting
These activities are influenced by several error producing conditions (EPCs) defined by [29]. For example, “Ambiguity in the required performance standards” EPC 11 has influenced 33 out of the 35 activities. Therefore, in order to reduce the HEP values and increase the process plant availability, these EPCs should be reduced or eliminated. Since the HEP values are not ALARP, these HEP values will be reduced by using the H-DMG. For example, the maintenance activity (IPT7), “Perform pressure test & isolation valves”, is located in the critical zone. In order to reduce the HEP value of this activity, there is a need to improve the supervision of this task, reduce the task complexity, and improve the procedure.
The simulation results can be seen in Table 3, It can be noticed that the mean availability of the improved process plant is increased to 93.1% over a period of 10 years. Additionally, the total downtime during these ten years is reduced to 5,440 hours, and the number of failures is reduced to 105 failures. This can be considered as a good improvement of the recommended HECMs are followed. In fact, it can be noticed that the estimated total downtime cost has been reduced to almost £109 million. A total of £28 million can be saved if human errors can be reduced. Further, in order to meet the target of this study, some further technical improvements are required.
Table 3 Simulation results for the first improvement
| System Overview | |
| Mean Availability (All Events): | 93.1% |
| Expected Number of Failures: | 105 |
| CM Downtime (Hr): | 5,440 |
| System Total Cost: | £109m |
Improvement Two: Improved offshore oil and gas topside systems by reducing HEP and implementing system redundancy
Although the previous scenario improved the process plant’s availability, this study’s targets are still not met. Therefore, there is a need to improve the system by identifying critical assets that have a significant impact on the process plant unavailability. According to the simulation results, a single compressor is responsible for 11% of the process plant unavailability. This is followed by the export pumps which are responsible for 9.02% of the process plant unavailability. Several maintenance strategies and decisions can be taken based on an organisation’s available resources, budgets, and investments to improve the system. For demonstration purposes, an active redundant gas compression train is added, and active redundant export pumps are added.
The simulation results can be seen in Table 4. It can be noticed that the mean availability of the improved process plant is increased to 95.4% over a period of 10 years. Additionally, the total downtime during these ten years is significantly reduced to 3,635 hours, and the number of failures is reduced to 70 failures. Further, it can be noticed that the estimated total downtime cost has been reduced to almost £73 million. A total of £63.3 million can be saved if both human errors can be reduced, active redundant systems are included.
Table 4 Simulation results for the second improvement
| System Overview | |
| Mean Availability (All Events): | 95.4% |
| Expected Number of Failures: | 70 |
| Corrective Maintenance Downtime (Hr): | 3,635 |
| System Total Cost: | £73m |
4.3 Validation of the framework #
Based on the previous assumptions and assessments, this research has simulated four different scenarios for an offshore oil and gas process plant. In order to validate the developed framework, comparative analyses were carried out to evaluate the proceed plant. It is a standard practice in industry to perform a RAM study by using simulation methods for a piece of equipment during the design or operation phase. The simulation’s results of this study can be benchmarked against a publicly available similar study and then validated by subject-matter experts.
5 Discussion #
The RAMS analysis objectives are: providing a prediction of a system’s behaviour to meet design specifications; assessing the life-cycle costs of a system; and identifying critical systems or components that can cause undesirable consequences. Based on the finding of the literature review and some informal interviews with senior reliability engineers in industry, human errors in maintenance are not considered during a RAM analysis [22]. This issue has been considered as one of the motivations to conduct this research. Although a RAM study can have several advantages, analysts might face some limitations when conducting a RAM study [19]:
- There is a degree of uncertainty when estimating reliability values
- Reliability models depend heavily on historical data
- A tremendous amount of data points is required to form a statistical distribution
- When predicting future events, there is a need to assume that operating conditions of simulated systems are similar to the current situation
- Often, failure and repair rates are assumed to be constant. This is not always the case
- A RAM study might require a tremendous amount of resource
- There is a possibility to underestimate or overestimate failure and repair rates which can affect the predicted availability of a system
In addition, when applying a human reliability assessment, analysts might face some limitations, such as [10]:
- Reliable information and data might be lacking
- PSFs can be insufficiently selected.
- Cognitive behaviours are inadequately estimated.
- There is a great focusing on human errors, not the causes.
- Experimental data is not sufficient for validation and modelling.
It can be noticed that the top five HECMs are: improve supervision, improve team communication and documentation, improve training and enhance competence, reduce task complexity, and improve /design out procedure. This outcome was consistent with the findings of the literature review. In fact, organisations should invest in implementing these improvement measures in order to reduce the probability of human errors in maintenance activities. Therefore, the H-DMG can be used as a map to improve maintenance activities by selecting the appropriate HECMs based on the magnitude of HEP and Ha-MTTR.
Initially, the developed framework was theoretically validated by using a simulation case study. This case study has used publicly available data to simulate an offshore oil and gas process plant. The output of this simulation has proven that the developed framework can reduce human error probabilities in maintenance activities and improve the availability of a system.
The results of this simulation can be benchmarked against a publicly available similar study [47]. Also, the framework was validated by subject-matter experts in the field of human factor and reliability engineering. The first two human factor specialists are HRA authors and have an experience of 25 years in a high-risk industry. The other four experts are senior engineers and managers in the field of reliability engineering. This validation process was conducted by using several interviews where the research was fully presented to them. They have had a chance to ask questions for further clarification if needed. Then, the experts completed a feedback form, which can be used as a means of validation.
5 Conclusion #
Human errors can be significant contributors to the overall risk in the industry. Human errors, in fact, are often a root or significant cause of a system failure which could lead to tremendous undesirable consequences. Although most industries use the latest technologies in order to maximise the availability and reliability of their equipment and minimise human interventions, the human role is still vital in different phases of a plant life cycle, especially during maintenance activities. Traditional RAM methodology did not incorporate human reliability analysis. Therefore, this research developed a novel framework for improved maintenance engineering decision-making, which was achieved by fusing probabilistic human and hardware availability assessment techniques. Initially, the proposed framework has a systematic process that can reduce HEPs in maintenance activities and improve the availability of a system. A publicly available case study in an offshore oil and gas platform was selected as an example for demonstration and validation purposes. The output of this case study has proven that the developed framework can reduce HEP by 35% and reduce the downtime cost by 45%. Also, the framework was validated by subject-matter experts in the field of human factor and reliability engineering. These experts have found that the developed framework can be easily applied and has great potential applications in the industry. Finally, it was not possible to apply and validate the developed framework on a field case study due to time constraints; however, this research recommended utilising this framework on a full-scale case study for further validation and enhancement.
References #
- J. Moubray, Reliability-centered Maintenance, 2nd ed., Oxford, UK: Elsevier Ltd, 1997.
- V. Roblek, M. Meško and A. Krapež, “A Complex View of Industry 4.0,” SAGE Open, vol. 6, no. 2, pp. 1-11, 2016.
- Y. Lu, “Industry 4.0: A survey on technologies, applications and open research issues,” Journal of Industrial Information Integration, vol. 6, pp. 1-10, 2017.
- C. Schröder, “The Challenges of Industry 4.0 for Small and Medium-sized Enterprises,” FRIEDRICH-EBERT- STIFTUNG, Bonn , 2016.
- D. Komljenovic, M. Gaha, G. Abdul-Nour, C. Langheit and M. Bourgeois, “Risks of extreme and rare events in Asset Management,” Safety Science, vol. 88, pp. 129-145, 2016.
- A. Ferlin, S. Qiu, P. Bon, M. Sallak, S. Dutilleul, W. Schön and Z. Cherfi-Boulanger, “An Automated Method for the Study of Human Reliability in Railway Supervision Systems,” IEEE Transactions on Intelligent Transportation Systems, vol. PP, no. 99, pp. 1 – 16, 2018.
- R. Islam, R. Abbassi, V. Garaniya and F. Khan, “Development of a human reliability assessment technique for the maintenance procedures of marine and offshore operations,” Journal of Loss Prevention in the Process Industries, vol. 50, p. 416–428, 2017.
- Q. Zhou, Y. Wong, H. Loh and K. Yuen, “A fuzzy and Bayesian network CREAM model for human reliability analysis – The case of tanker shipping,” Safety Science, vol. 105, p. 149–157, 2018.
- R. G. Bea, “Design for Reliability: Human and Organisational Factors,” in Handbook of Offshore Engineering, S. Chakrabarti, Ed., Oxford, Elsevier Ltd., 2005, pp. 939-999.
- P. Baziuk, J. Mc Leod, R. Calvo and S. Rivera, “Principal Issues in Human Reliability Analysis,” in Lecture Notes in Engineering and Computer Science: Proceedings of The World Congress on Engineering, London,UK, 2015.
- X. Sun, R. Houssin, J. Renaud and M. Gardoni , “A review of methodologies for integrating human factors and ergonomics in engineering design,” International Journal of Production Research, 2018.
- D. Smith, Reliability, Maintainability and Risk, 8th ed., Oxford: Butterworth-Heinemann, 2011.
- A. W. Labib, Integrated and interactive appropriate productive maintenance, PhD thesis, Birmingham,UK: University of Birmingham, 1996.
- A. W. Labib and M. Yuniarto, “Maintenance strategies for changeable manufacturing,” in Changeable and reconfigurable manufacturing systems, H. A. ElMaraghy, Ed., London, Springer, 2008, pp. 327-351.
- A. Shahin and M. Attarpour, “Developing Decision Making Grid for Maintenance Policy Making Based on Estimated Range of Overall Equipment Effectiveness,” Modern Applied Science, vol. 5, no. 6, pp. 86-97, 2011.
- M. Sheikhalishahi, L. Pintelon and A. Azadeh, “Human factors in maintenance: a review,” Journal of Quality in Maintenance Engineering, vol. 22, no. 3, pp. 218-237, 2016.
- Z. Tahir, M. A. Burhanuddin, A. R. Ahmad, S. M. Halawani and F. Arif, “Improvement of Decision Making Grid Model for Maintenance Management in Small and Medium Industries,” in International Conference on Industrial and Information Systems (ICIIS), Sri Lanka, 2009.
- D. Smith, Reliability, Maintainability and Risk: Practical Methods for Engineers, 9th ed., Oxford: Butterworth- Heinemann, 2017.
- S. Woo, Reliability Design of Mechanical Systems: A Guide for Mechanical and Civil Engineers, Cham, Switzerland: Springer International Publishing, 2017.
- T. Tinga, Principles of Loads and Failure Mechanisms, London: Springer, 2013.
- J.-M. Flaus, Risk Analysis: Socio-technical and Industrial Systems, London: ISTE Ltd., 2013.
- E. Calixto, Gas and Oil Reliability Engineering: Modeling and Analysis, 2nd ed., Oxford: Gulf Professional Publishing, 2016.
- M. Havlikova, M. Jirgl and Z. Bradac, “Human Reliability in Man-Machine Systems,” in 25th DAAAM International Symposium on Intelligent Manufacturing and Automation, Vienna, 2015.
- NEA, “Human reliability analysis in probabilistic safety assessment for nuclear:CSNI technical opinion papers 4,” Nuclear Energy Agency, Paris, 2004.
- R. W. McLeod, Designing for Human Reliability: Human Factors Engineering in the Oil, Gas, and Process Industries, Oxford: Elsevier Ltd., 2015.
- A. Petrillo, D. Falcone, F. De Felice and F. Zomparelli, “Development of a risk analysis model to evaluate human error in industrial plants and in critical infrastructures,” International Journal of Disaster Risk Reduction, vol. 23, p. 15–24, 2017.
- A. D. Swain and H. E. Guttmann, Handbook of human reliability analysis with emphasis on nuclear power plant applications, Washington, DC.: US Nuclear Regulatory Commission, 1983.
- A. D. Swain, Accident Sequence Evaluation Program Human, Washington, DC.: US Nuclear Regulatory Commission, 1987.
- J. C. Williams, “HEART – a proposed method for assessing and reducing human error,” in 9th Advances in Reliability, University of Bradford, 1986.
- D. Gertman, H. Blackman, J. Marble, J. Byers and C. Smith, “The SPAR-H Human Reliability Analysis Method,” Idaho National Laboratory, Idaho Falls, Idaho , 2005.
- S. Cooper, A. Ramey-Smith, J. Wreathall, G. Parry, D. Bley, W. Luckas, J. Taylor and M. Barriere, “A Technique for Human Error Analysis (ATHEANA) – Technical Basis and Methodological Description,” NUREG/CR-6350 Brookhaven National Laboratory, Upton, NY, 1996.
- E. Hollnagel, Cognitive Reliability and Error Analysis Method (CREAM), Oxford : Elsevier Ltd, 1998.
- M. Rausand, RISK ASSESSMENT Theory, Methods, and Applications, New Jersey: John Wiley & Sons, Inc, 2011.
- N. Paltrinieri, S. Massaiu and A. Matteini, “Human Reliability Analysis in the Petroleum Industry,” in DYNAMIC RISK ANALYSIS IN THE CHEMICAL AND PETROLEUM INDUSTRY, N. PALTRINIERI and F. KHAN, Eds., Oxford, Butterworth-Heinemann, 2016, pp. 181-192.
- B. S. Dhillon, Human Reliability, Error, and Human Factors in Power Generation, Cham, Switzerland: Springer International Publishing, 2014.
- J. Rasmussen, “Skills, rules, knowledge: signals, signs and symbols and other distinctions in human performance models,” IEEE Transactions on Systems, Man and Cybernetics, vol. 13, p. 257–267, 1983.
- J. Reason, Human Error, Cambridge: Cambridge University Press, 1990.
- B. S. Dhillon and Y. Liu, “Human error in maintenance: a review,” Journal of Quality in Maintenance Engineering,vol. 12, no. 1, pp. 21-36, 2006.
- Y. Ngadiman, B. Hussin, N. Abd Hamid, R. Ramlan and L. Boon, “Relationship between Human Errors in Maintenance and Overall Equipment Effectiveness in Food Industries,” in International Conference on Industrial Engineering and Operations Management, Kuala Lumpur, 2016.
- A. Antonovsky, C. Pollock and L. Straker, “Identification of the Human Factors Contributing to Maintenance Failures in a Petroleum Operation,” The Journal of the Human Factors and Ergonomics Society, vol. 56, no. 2, p. 306–321, 2014.
- A. W. Labib, “World-class maintenance using a computerised maintenance management system,” Journal of Quality in Maintenance Engineering, vol. 4, no. 1, pp. 66-75, 1998.
- A. W. Labib, “A decision analysis model for maintenance policy selection using a CMMS,” Journal of Quality in Maintenance Engineering, vol. 10, no. 3, pp. 191-202, 2004.
- W. Lyons, G. Plisga and M. Lorenz, Standard Handbook of Petroleum and Natural Gas Engineering, 3rd ed., Waltham, MA: Gulf Professional Publishing, 2016.
- OREDA, OREDA: Offshore Reliability Data, 5th ed., Trondheim: Det Norske Veritas (DNV), 2009.
- T.-V. Nguyen, M. Voldsun, P. Breuhaus and B. Elmegaard, “Energy efficiency measures for offshore oil and gas platforms,” Energy, vol. 17, no. 2, pp. 325-340, 2016.
- A. Noroozi, F. Khan, S. MacKinnon, P. Amyotte and T. Deacon, “Determination of human error probabilities in maintenance procedures of a pump,” Process Safety and Environmental Protection, vol. 92, p. 131–141, 2014.
- E. Zio, P. Baraldi and E. Patelli, “Assessment of the availability of an offshore installation by Monte Carlo simulation,” International Journal of Pressure Vessels and Piping, vol. 83, p. 312–320, 2006.



